추천 시스템에서 유사도 계산은 매우 중요한 단계입니다. 유사도를 계산하는 방법에는 다양한 수학적 방법이 있으며, 각 방법은 데이터의 특성과 상황에 따라 적합성이 달라집니다. 아래에서는 대표적인 유사도 계산 방법을 소개하고 자세히 설명하겠습니다.
1. 코사인 유사도 (Cosine Similarity)
개념
코사인 유사도는 두 벡터 간의 방향의 유사도를 측정합니다. 두 벡터가 이루는 각도의 코사인을 계산하여 유사도를 나타냅니다.
- 값의 범위: -1(반대 방향) ~ 1(같은 방향)
- 보통 추천 시스템에서는 값이 0에서 1 사이로 나타납니다.
공식

예시
아이템 간 유사도를 계산:
# 아이템 피처 행렬
초콜릿 | 견과류 | 짠맛
아몬드빼빼로 1 | 1 | 0
오징어땅콩 0 | 1 | 1코사인 유사도 계산:
Cosine Similarity(아몬드빼빼로, 오징어땅콩)=

2. 유클리드 거리 (Euclidean Distance)
개념
유클리드 거리는 두 벡터 간의 직선 거리를 측정합니다. 값이 작을수록 두 벡터가 더 유사하다고 간주합니다.
- 값의 범위: ~ ∞(무한대) (작을수록 유사).
공식

예시
위의 아이템 피처 행렬을 기준으로 계산:
Euclidean Distance(아몬드빼빼로, 오징어땅콩)=

3. 피어슨 상관계수 (Pearson Correlation Coefficient)
개념
피어슨 상관계수는 두 벡터 간의 선형 상관성을 측정합니다. 값이 1에 가까울수록 강한 양의 상관관계를, -1에 가까울수록 강한 음의 상관관계를 나타냅니다.
- 값의 범위: -1 ~ 1
공식
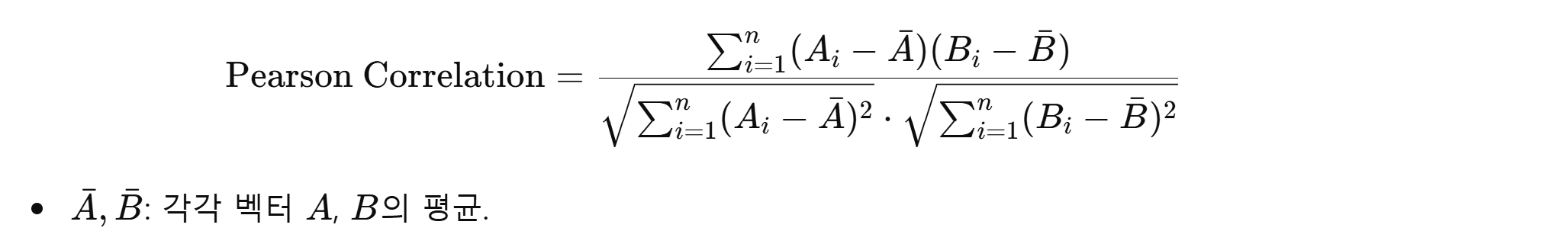
예시
유저가 평가한 아이템 평점을 기반으로 계산:
# 사용자 평점 행렬
아몬드빼빼로 | 오징어땅콩 | 치토스
유저1 5 | 4 | 3
유저2 4 | 3 | 3계산:
1) 벡터 평균:
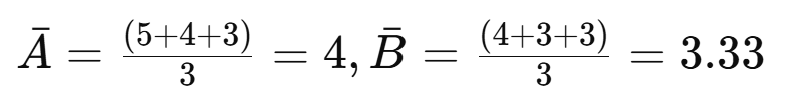
2) 피어슨 상관계수:
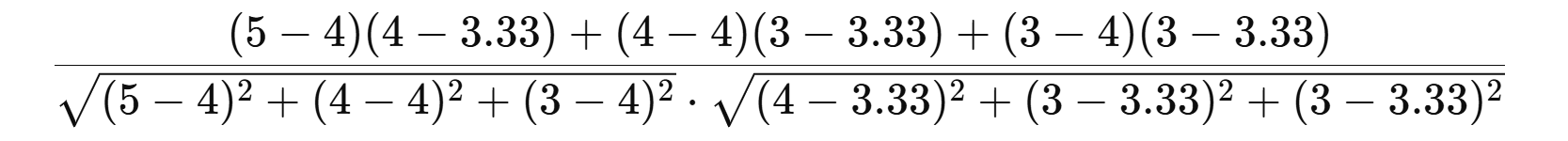
4. 맨해튼 거리 (Manhattan Distance)
개념
맨해튼 거리는 절대 거리를 사용하여 두 벡터 간의 차이를 측정합니다.
- 값의 범위: 0 ~ ∞ (작을수록 유사).
공식
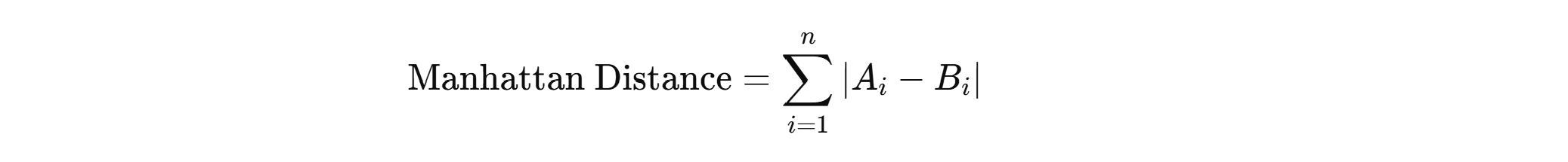
예시
위의 아이템 피처 행렬을 기준으로 계산:
Manhattan Distance(아몬드빼빼로, 오징어땅콩)=

유사도 계산 방법 선택 기준
- 코사인 유사도:
- 벡터 간의 크기보다는 방향이 중요한 경우.
- 일반적으로 텍스트 데이터에서 많이 사용.
- 유클리드 거리:
- 데이터의 절대적인 크기 차이를 강조할 때.
- 좌표 데이터나 물리적 거리 계산에 적합.
- 피어슨 상관계수:
- 데이터 간의 선형 관계를 측정할 때.
- 평점 데이터 등에서 널리 사용.
- 맨해튼 거리:
- 데이터 간 절대적 차이를 측정할 때.
- 계산이 간단하고, 희소 행렬에서 효율적.
'추천 시스템 > 이론' 카테고리의 다른 글
| 머신러닝 기반 추천 알고리즘 (1) | 2024.11.28 |
|---|---|
| 컨텐츠 기반 필터링과 협업 필터링 (0) | 2024.11.27 |
| 고전적인 추천 알고리즘: 연관 규칙 기반 추천 (Association Rule Mining) (0) | 2024.11.26 |
| 고전적 추천 알고리즘 (0) | 2024.11.26 |
| 추천 시스템이란? (0) | 2024.11.25 |