https://school.programmers.co.kr/learn/courses/30/lessons/258712
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
🔍문제 설명
[가장 많이 받은 선물]
선물을 직접 전하기 힘들 때 카카오톡 선물하기 기능을 이용해 축하 선물을 보낼 수 있습니다. 당신의 친구들이 이번 달까지 선물을 주고받은 기록을 바탕으로 다음 달에 누가 선물을 많이 받을지 예측하려고 합니다.
ㆍ 두 사람이 선물을 주고받은 기록이 있다면, 이번 달까지 두 사람 사이에 더 많은 선물을 준 사람이 다음 달에 선물을 하나 받습니다.
- 예를 들어 A가 B에게 선물을 5번 줬고, B가 A에게 선물을 3번 줬다면 다음 달엔 A가 B에게 선물을 하나 받습니다.
ㆍ 두 사람이 선물을 주고받은 기록이 하나도 없거나 주고받은 수가 같다면, 선물 지수가 더 큰 사람이 선물 지수가 더 작은 사람에게 선물을 하나 받습니다.
- 선물 지수는 이번 달까지 자신이 친구들에게 준 선물의 수에서 받은 선물의 수를 뺀 값입니다.
- 예를 들어 A가 친구들에게 준 선물이 3개고 받은 선물이 10개라면 A의 선물 지수는 -7입니다. B가 친구들에게 준 선물이 3개고 받은 선물이 2개라면 B의 선물 지수는 1입니다.
- 만약 A와 B가 선물을 주고받은 적이 없거나 정확히 같은 수로 선물을 주고받았다면, 다음 달엔 B가 A에게 선물을 하나 받습니다.만약 두 사람의 선물 지수도 같다면 다음 달에 선물을 주고받지 않습니다.
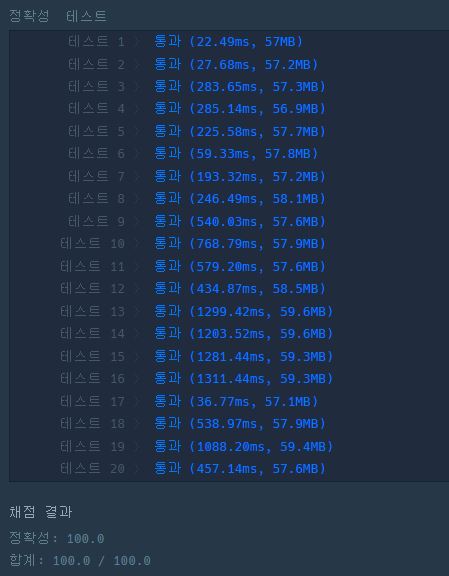
위에서 설명한 규칙대로 다음 달에 선물을 주고받을 때, 당신은 선물을 가장 많이 받을 친구가 받을 선물의 수를 알고 싶습니다.
friends: 친구들의 이름을 담은 1차원 문자열 배열
gifts: 이번 달까지 친구들이 주고받은 선물 기록을 담은 1차원 문자열 배열
⇨ 이때, 다음달에 가장 많은 선물을 받는 친구가 받을 선물의 수를 return 하도록 solution 함수를 완성해 주세요.
🔑문제 풀이
import pandas as pd
from copy import deepcopy
def solution(friends, gifts):
answer = 0
gift_list = []
for item in gifts:
gift_list.append(item.split(" "))
# 주고 받은 기록을 저장 할 df
data_df = pd.DataFrame(index = friends,columns=friends, data = 0)
for human in gift_list:
data_df.loc[human[0], human[1]] = 1 + data_df.loc[human[0], human[1]]
# 선물지수를 저잘할 df
data_df_count = deepcopy(data_df)
for item in friends:
data_df_count.loc[item, '준 선물'] = sum(data_df.loc[item])
data_df_count.loc[item, '받은 선물'] = sum(data_df[item])
data_df_count.loc[item, '선물 지수'] = data_df_count.loc[item, '준 선물'] - data_df_count.loc[item, '받은 선물']
data_df_count = data_df_count[['준 선물','받은 선물','선물 지수']]
# 받을 선물 결과를 저장할 df
result_df = pd.DataFrame(index = friends, columns=['받는 개수'], data = 0)
for giver in friends:
for recipient in friends:
giver_to_recipient = data_df.loc[giver, recipient]
recipient_to_giver = data_df.loc[recipient, giver]
if giver_to_recipient > recipient_to_giver:
result_df.loc[giver, '받는 개수'] = result_df.loc[giver, '받는 개수'] + 1
elif (giver_to_recipient == recipient_to_giver):
giver_ind = data_df_count.loc[giver, '선물 지수']
recipient_ind = data_df_count.loc[recipient, '선물 지수']
if giver_ind > recipient_ind:
result_df.loc[giver, '받는 개수'] = result_df.loc[giver, '받는 개수'] + 1
answer = int(result_df['받는 개수'].max())
return answer
| 문제를 풀때, 예시로 주어진 친구들의 관계를 나타낸 데이터프레임으로 만드는 것을 중점으로 생각하였습니다.
| 다 풀고 보니 개선할 점이 많아 보인다.
1) 제일 문제점은 데이터 프레임에 대해 반복문을 사용하여 행과 열을 순회하여 계산하는 것이라고 생각합니다. 반복문이 너무 많이 사용되어 코드가 복잡해 지는것 같습니다.
-> 벡터화 연산을 활용하여 문제를 풀었다면, 간결하고 효율적으로 계산이 될 것 같습니다.
2) 변수명을 만드는데 너무 어려웠습니다. 변수명이 너무 길어지는 경향이 있습니다
-> 변수명 짓는 연습을 통해, 더욱 직관적이고 가독성을 생각해야 할 것 같습니다.
'코딩테스트' 카테고리의 다른 글
| SQL 코딩테스트 연습_프로그래머스_Level2 / 재구매가 일어난 상품과 회원 리스트 구하기 (0) | 2025.02.21 |
|---|---|
| SQL 코딩테스트 연습_프로그래머스_Level2 / 조건에 맞는 개발자 찾기 (0) | 2025.02.20 |
| SQL 코딩테스트 연습_프로그래머스_Level3 / 대장균들의 자식의 수 구하기 (0) | 2025.02.20 |
| SQL 코딩테스트 연습_프로그래머스_Level3 / 대장균의 크기에 따라 분류하기 1 (0) | 2025.02.17 |
| 코딩테스트 연습_프로그래머스 [PCCP 기출문제] 1번 / 동영상 재생기 (1) | 2024.10.08 |